ES 深度分页
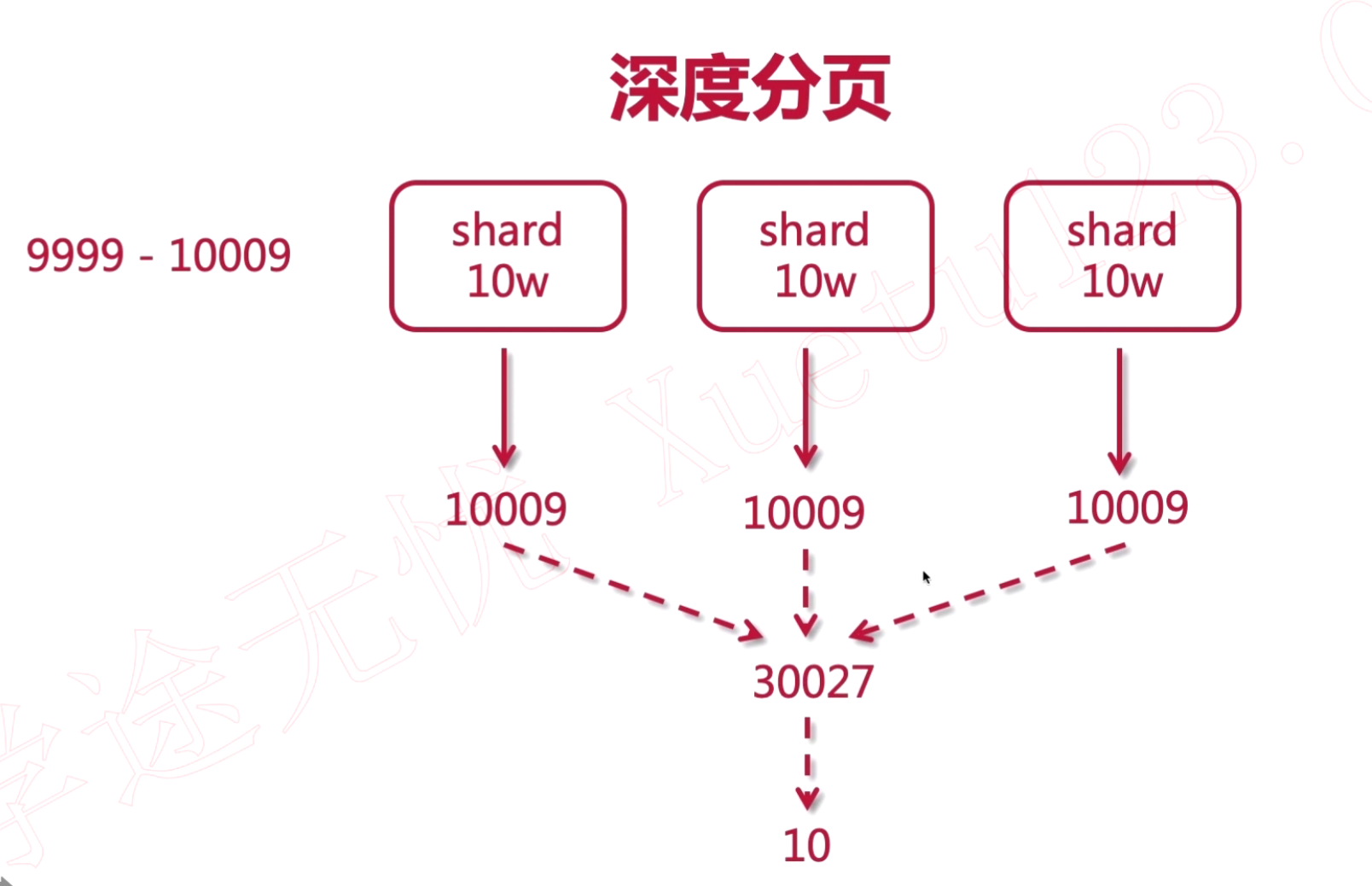
正常的使用from和size去分页查询的时候,from+size的结果要小于10000,因为ES内部考虑到性能的因素,对此做了限制。 ES在查询数据的时候,例如获取9999-10009的数据时,他的from=9999,size=10,假如有3个shard,每个shard有10W条数据,他会从每个shard获取10009条数据,合成一个结果集,在从这个结果集中取10条数据,剩下的30017条数据就会丢弃,这么做的缺点会造成资源和性能的浪费。
针对上述问题,可以使用限制总页数的方式去规避,查询大于10000条数据的问题,例如,查询页数,限制在最大100页。
突破10000条数据的限制
如果在某些企业内部,对查询数据有特殊的要求,对于性能没有必要的要求的话,可以通过修改配置来突破10000数据的查询限制。
查询配置信息的方法
| 名称 | 数值 | 备注 |
|---|---|---|
| 请求地址 | http://192.168.3.214:9200/shop/_settings | |
| 请求类型 | GET |
修改配置
| 名称 | 数值 | 备注 |
|---|---|---|
| 请求地址 | http://192.168.3.214:9200/shop/_settings | shop:索引 |
| 请求方式 | put | |
| 参数类型 | json | |
| 请求参数 | 见下方请求参数 | |
| 响应类型 | json | |
| 响应数据 | 见下方响应数据 |
请求参数
{
"index.max_result_windows": 100000
}
响应数据
{
"acknowledged": true
}
Scroll 滚动搜索
上面通过对配置的修改来获取大数据量的搜索,对性能上是有影响,实际生产上是不推荐这么做的,我们还可以通过使用scroll滚动搜索的方式来查询大数据量的搜索工作。
滚动搜索原理
可以把 scroll 理解爲关系型数据库里的 cursor,因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。 scroll 具体分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。游标可以增加性能的原因,是因为如果做深分页,每次搜索都必须重新排序,非常浪费,使用scroll就是一次把要用的数据都排完了,分批取出,因此比使用from+size还好。
搜索示例
| 名称 | 数值 | 备注 |
|---|---|---|
| 请求地址 | http://192.168.3.214:9200/shop/_search?scroll=1m | scroll表示滚动时间,也就是说缓存起来的数据的有效期,这里设置的是1分钟。 |
| 请求类型 | POST | |
| 请求参数 | 见下方请求参数 |
请求参数
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 5 # 每次滚动的数据数量
}
第一次查询会返回一个scroll_id,在第二次滚动查询时,需要带上这个scroll_id。
第二次滚动搜索
| 名称 | 数值 | 备注 |
|---|---|---|
| 请求地址 | http://192.168.3.214:9200/_search/scroll | |
| 请求类型 | POST |
{
"scroll_id": "SGsguighdasdhkHSkhdashkd==",
"scroll": "1m"
}
每一次滚动查询,都要将上一次查询的scroll_id携带过来,直到查询得结果集为空。 上面设置的size是作用于单个分片,所以如果有多个分片的话,每次实际返回的文档数量最大为:size * 分片数量