Elasticsearch原理
Lucene
Lucene是一个代码库,使用Java开发的搜索引擎,不利于分布式拓展。
Solr
Slor是基于Lucene开发的搜索引擎,是apache开源的搜索引擎,只支持Java。
Elasticsearch
ES也是基于Lucene开发,支持分布式,以及多种语言,拓展性比较好。支持TB级别的搜索(TB级别是1024T容量查询)。 ES是基于文档去检索的。
ES核心术语
- 索引 Index
- 相当于数据库的表
- 类型 type
- 相当于表的逻辑类型,用于区分索引,ES 7.x已经不在使用了,老得版本还在使用
- 文档 document
- 相当于行,是json的形式去存在的
- 字段 fields
- 列
- 映射 mapping
- 相当于表结构定义
- 近实时 NRT
- Near real time 接近真实的时间,当新建一个文档之后,一般会有1秒左右的时间的延时
- 节点 node
- 每一个服务器,就是一个节点
- shard replica
- 数据分片与备份
集群相关
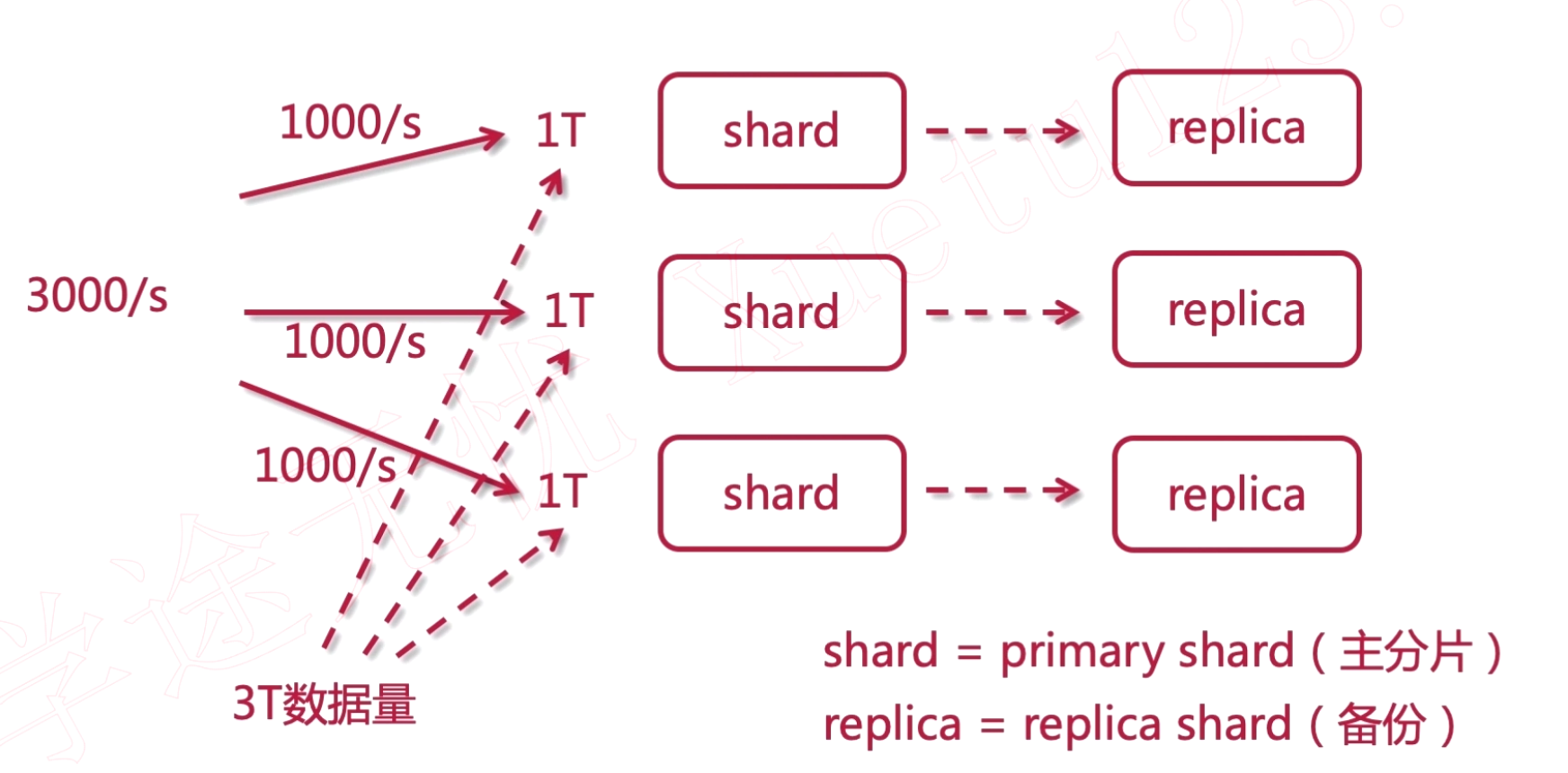
分片(shard):把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据内容加在一起是一个完整的索引库,分别保存到三个节点上,目的为了水平拓展,提高吞吐量。 备份(replica):每个shard的备份。
简称
shard = primary shard(主分片) replica = replica shard(备份节点)
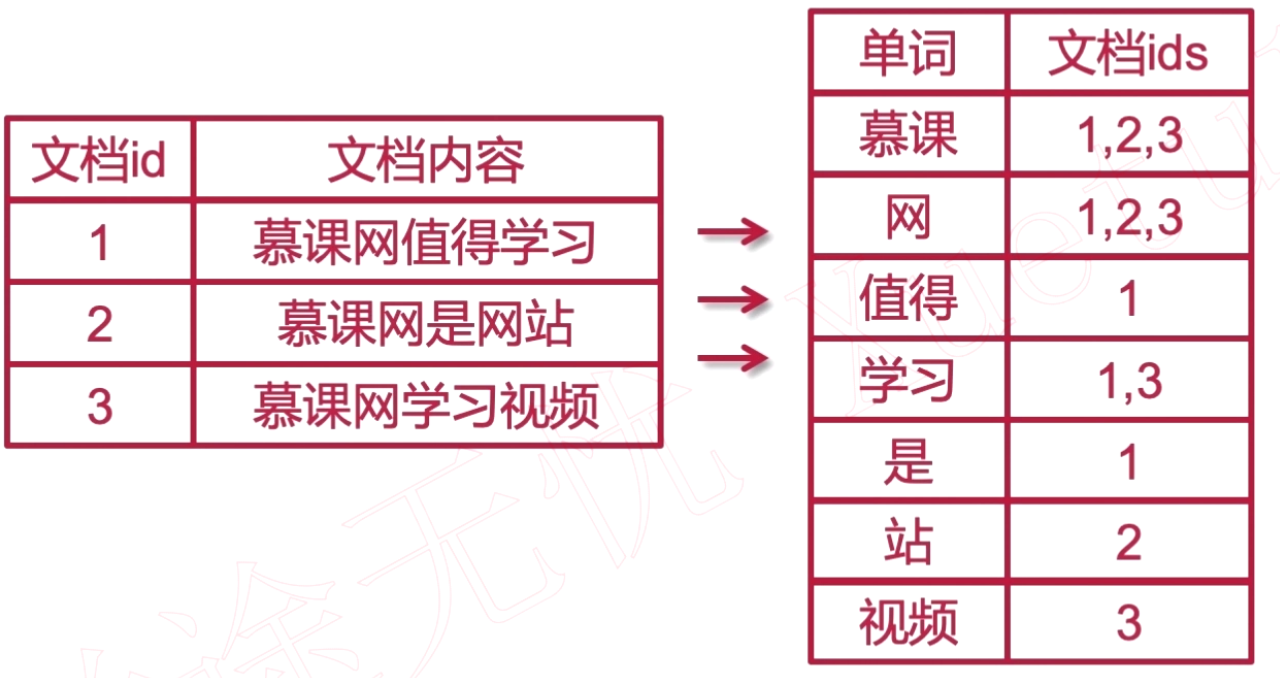
倒排索引
倒排索引就是将正排索引的文档内容进行分词,然后记录这个词在每个文档出现的文档ID。
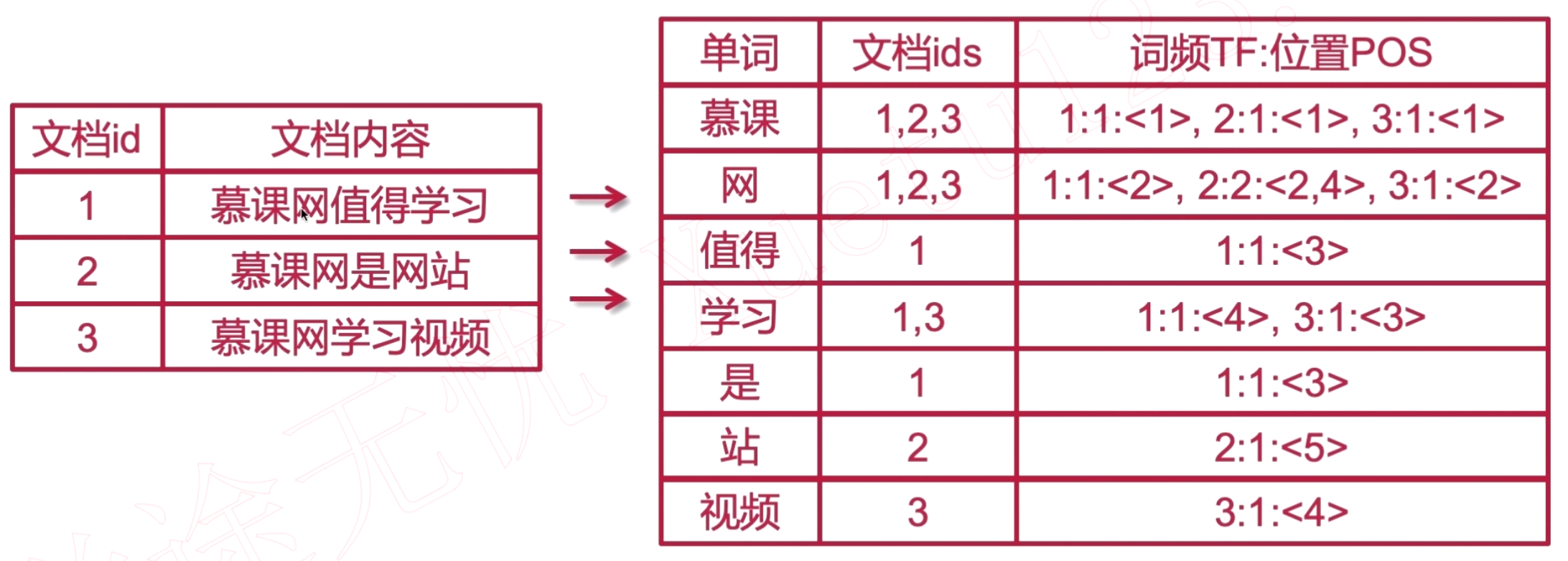
 词频TF:位置POS
词频是记录这个词在那个文档下出现的次数和位置,记录方法:1:1:<1>,表示文档ID1下,出现过1次,在下标为1的位置。
词频TF:位置POS
词频是记录这个词在那个文档下出现的次数和位置,记录方法:1:1:<1>,表示文档ID1下,出现过1次,在下标为1的位置。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括u一个属性值和包含该属性的各个记录地址。由于不是根据记录来确定属性,而是根据属性来确定记录的位置,所以称之为倒排索引。